JMP slide: A NOP-sled alternative
In the following blog post, I will introduce you to two techniques similar to NOP-sled or NOP slide, but with the advantage that they are faster. Those techniques are: JMP slide and JCC slide.
Start
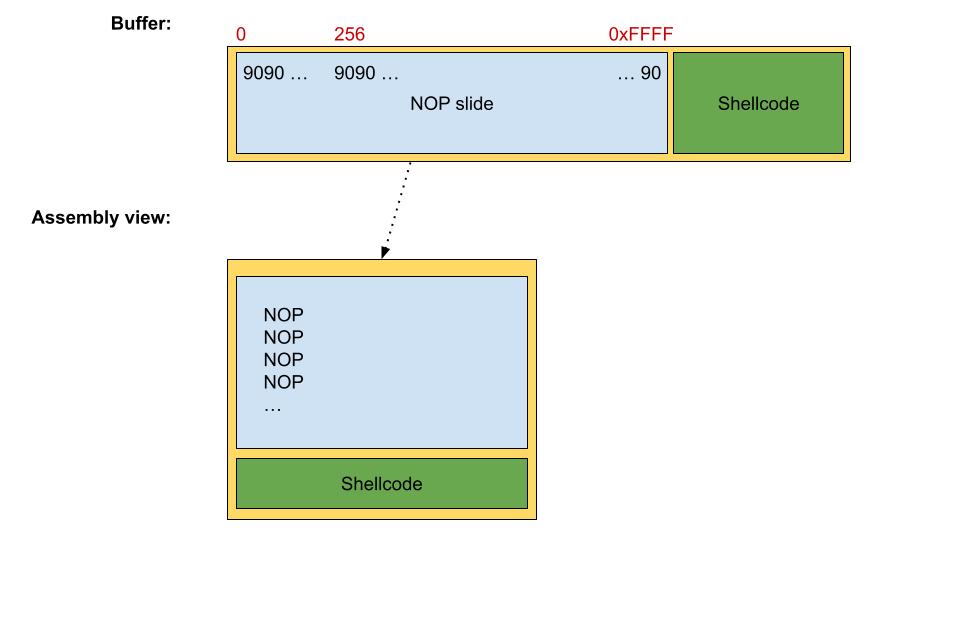
NOP slide
While developing my tool GDBleed, I came across to a problem related to exploit development, which is the notion of NOP-sled or NOP slide.
The NOP slide technique adds a large sequence of NOP instructions at the beginning of the exploit. This is done to enhance the exploit’s portability, because different versions of the same software might have the same vulnerability but with slightly different behaviors, and so the same redirected address might point to a different part of the exploit.
JMP slide
Now for reasons related to poor instrumentation techniques used in GDBleed, i had to instrument codes by calling an address, that i cannot know precesily, but i know the range, which is within the 0x0000-0xFFFF range. And so here comes the NOP slide solution, well not really. In the worst-case scenario, i wasted 0xFFFF cycles of CPU clocks, and so here comes the idea: Instead of having a large sequence of NOPs i will insert at the begining of the payload a long sequence of short jumps, which can update RIP by a maximum amount of 0x7F, whether in a negative or positive direction.
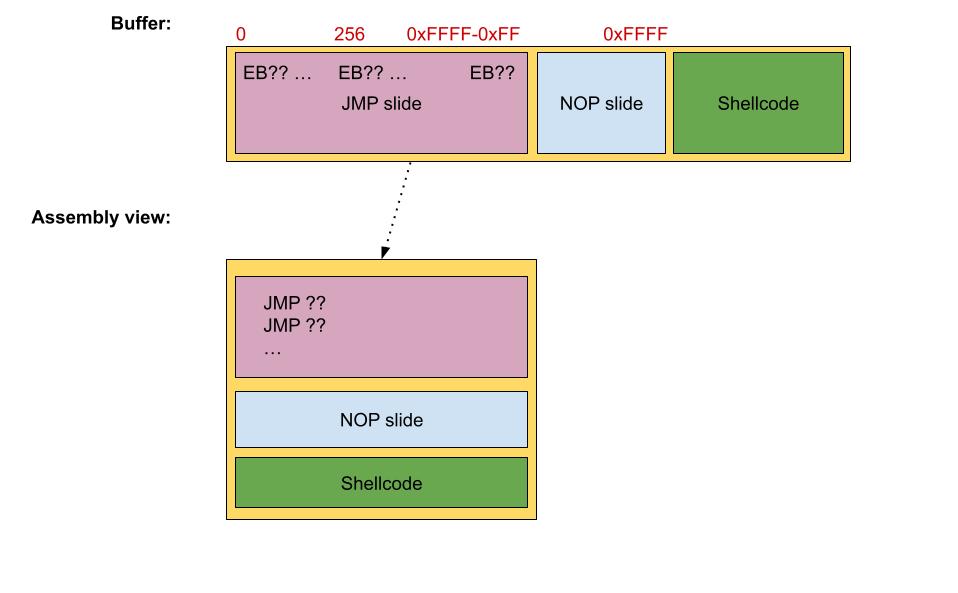
The problem with this solution is that the short jump occupies two bytes, one for the opcode, which is 0xEB, and one for the offset. So we have a 50% chance to execute the opcode and not the offset as the opcode. The first solution that came to my mind was to use as offset 0xEB or 0x90. In the first case it works because i know i will always execute a short jump. In the second case, it works because NOP occupies only one byte and, after being executed, would permit the execution of the short jump.
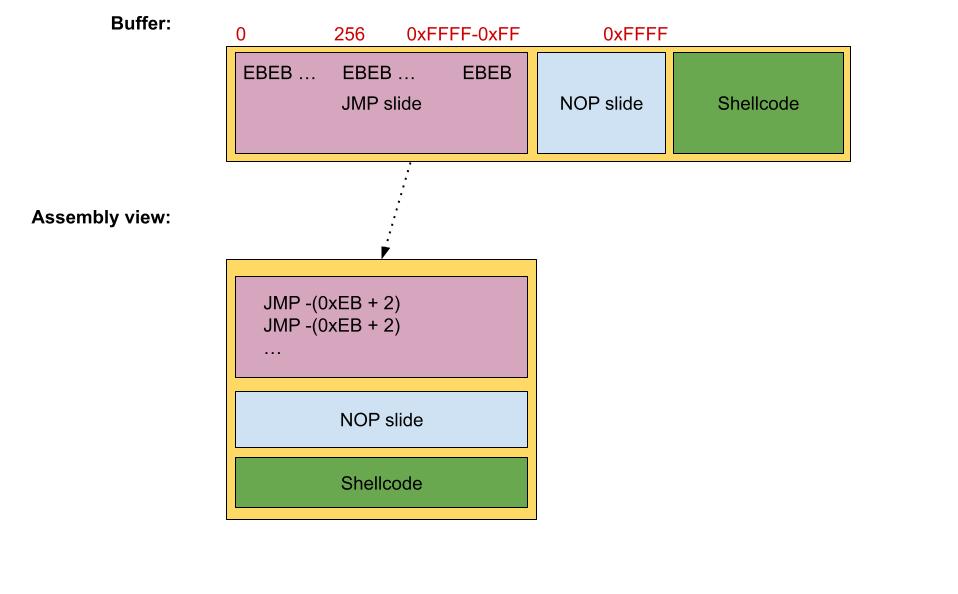
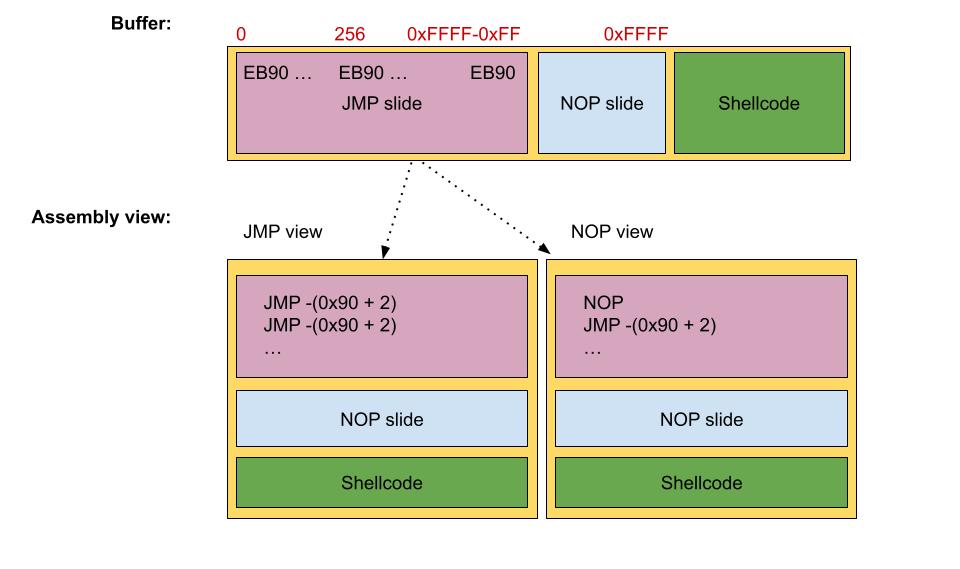
Both solutions mentioned will work only if the shellcode is positioned above in the payload, because the JMPs are using negative offsets. The figure should be changed as follows:
Intel’s JCC instructions
In my case, i had to select a positive sign offset that would still permit me to execute it as a normal instruction and would still give me the JMP slide sequence sprint. To my best knowledge, i could not find any one-byte non-negative instruction, and the two-byte ones, once executed, would disrupt the JMP sequence. The best solution i found was to use the opcodes in the range of 0x70-0x7F, which are reserved for some of the conditional branch instructions, that is, the JCC instructions.
The “Jump if Condition Is Met” instructions, abbreviated as JCC instructions, are contidional branch instruction, which means a jump is taken only if a condition is met. In intel x86, this condition is determined by the value of the EFLAGS register, (except for J*CXZ which jumps based on the RCX, ECX, CX registers).
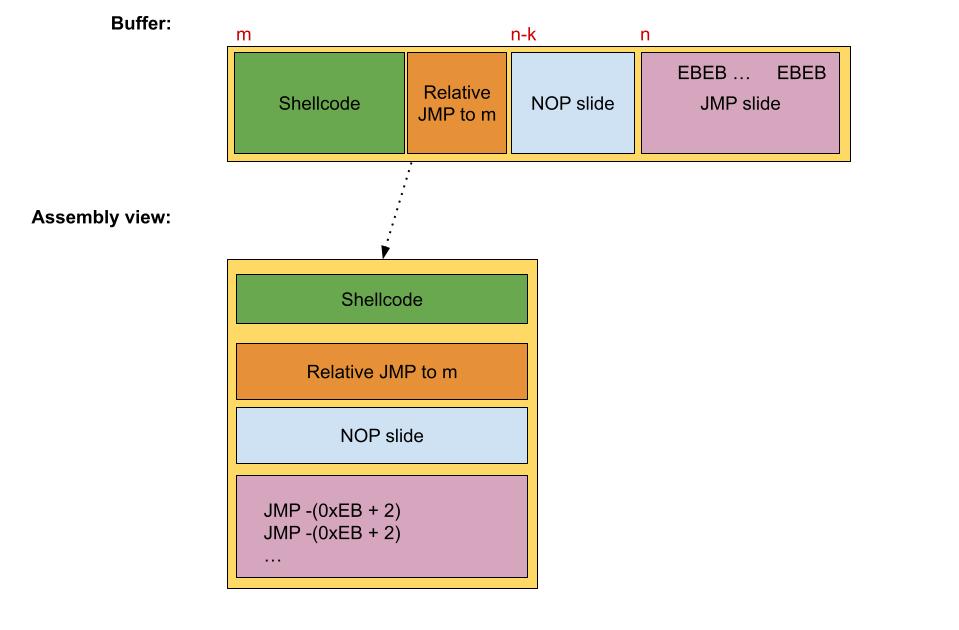
JMP-JCC slide
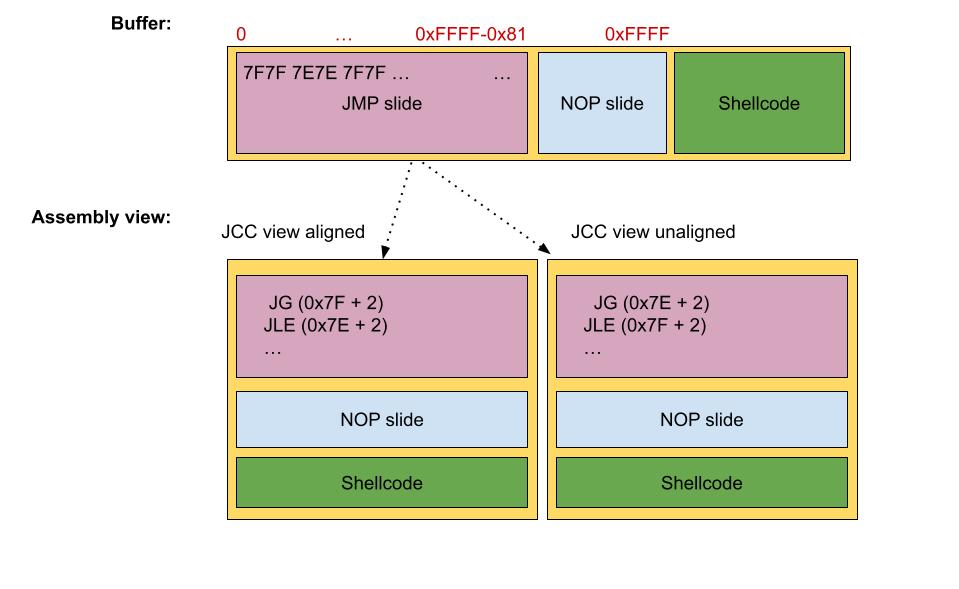
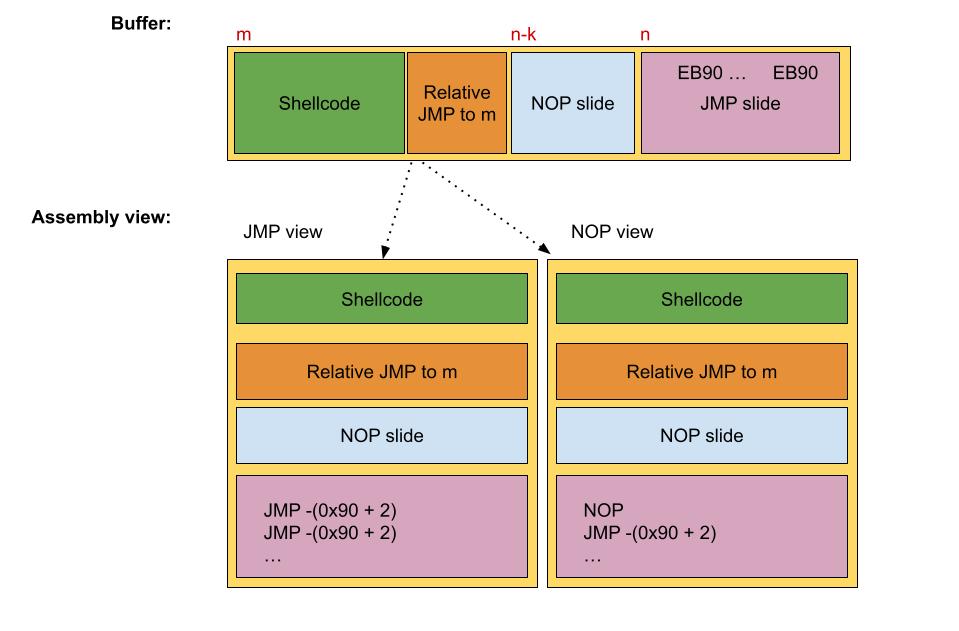
Except for the conditional behavior based on the EFLAGS register value, The short JCC instructions behave the same as the short JMP instructions. So back to the problem, we could use as the JMP’s offsets a valid JCC instruction, allowing us to not disrupt the JMP slide. Which short JCC instruction to use depends on the specific scenario. However, in the general case, EFLAGS could contain anything so it’s better to spam each short JCC instruction. The result is as follows:
This solution is not completely stable, as we have two perspectives when disassembling the same JMP-JCC slide. In the first view, we have JMP instructions using positive offsets in the range 0x70-0x7F, while in the second view, we have JCC instructions using a negative offset 0xEB, and so jumping backward. The figure below illustrates this example.
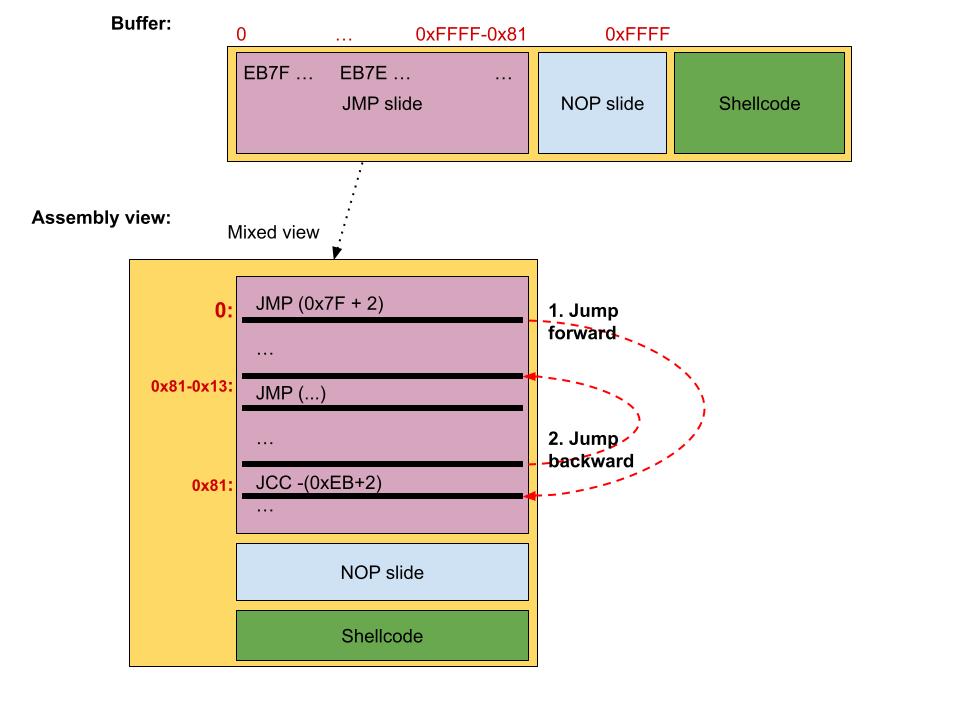
JCC slide
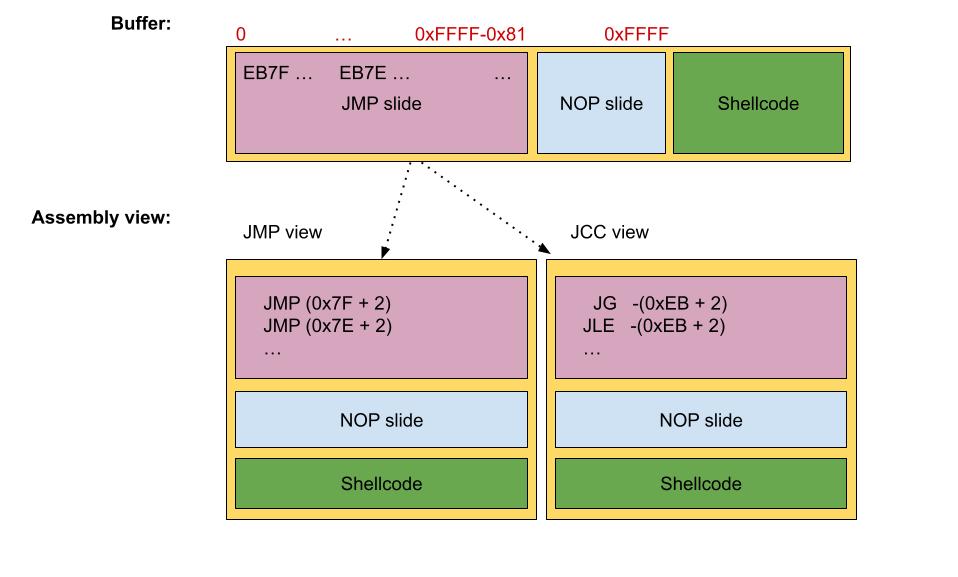
The JMP-JCC slide technique is not feasible, as it will slow down or, worse, get stuck the exploit. Instead of using a JMP slide, let’s use only short JCC instructions.
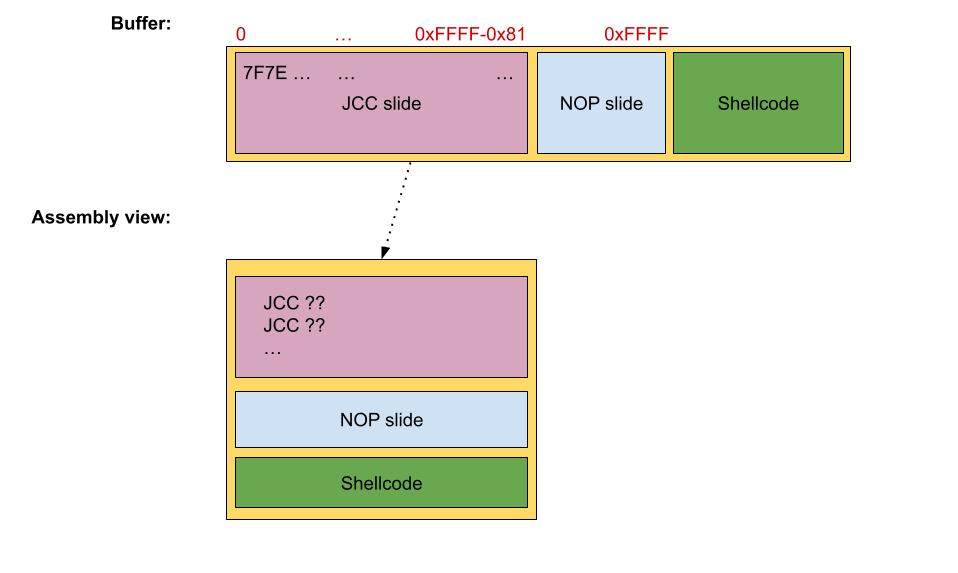
Cool. Now the only problem with this solution is that it can potentially hide some of the JCC instructions, also if the conditions to jump are never met, then the JCC slide will became a NOP-sled alike solution. To avoid this scenario, we insert twice each opcode, which will solve the problem.